
Geometry Complete Course
$297.00
What's Included:
Geometry Complete Course gives your student everything needed to earn a full high school geometry credit using the highly respected Harold Jacobs Geometry: Seeing, Doing, Understanding curriculum:
Clear video instruction from AskDrCallahan instructors, a structured plan, and built-in support for parents. This course helps students truly understand geometry.
Perfect for 9th or 10th grade honors math geometry credit.
A Complete, Parent-Friendly High School Geometry Course
Teach high school geometry at home with confidence.
The Geometry Complete Course gives your student everything needed to earn a full high school geometry credit using the highly respected Harold Jacobs Geometry: Seeing, Doing, Understanding curriculum.
With clear video instruction from AskDrCallahan, a structured weekly plan, and built-in support for parents, this course helps students truly understand geometry instead of simply memorizing formulas.
Perfect for 9th grade honors math or a standard 10th grade geometry credit.
✔ Clear, engaging geometry instruction
✔ Step-by-step video teaching
✔ Easy-to-follow weekly schedule
✔ Tests, solutions, and grading support included
✔ Homework help available when you need it
Everything you need to successfully teach high school geometry at home — all in one complete course.
Geometry That Builds Real Understanding
Many students struggle with geometry because they are asked to memorize formulas without understanding the ideas behind them.
Jacobs’ Geometry takes a completely different approach.
Through engaging explanations and real-world examples, students discover geometric concepts step by step. Instead of simply copying procedures, they learn the reasoning behind them.
Your student will learn to:
• Understand geometric concepts instead of memorizing formulas
• Apply geometry to real-life situations
• Develop logical thinking and problem-solving skills
• Work through geometric proofs with confidence
• Build a strong foundation for higher math and science
Video Instruction That Makes Difficult Concepts Clear
AskDrCallahan’s teaching videos guide students through the most challenging parts of the course in a clear, encouraging style.
Developed by a longtime university engineering professor, homeschool dad, and math instructor for homeschool groups, AskDrCallahan understands exactly where students tend to get stuck — and how to help them move forward with confidence.
Students benefit from:
• Clear explanations of key geometry concepts
• Step-by-step guidance through important problems
• A relaxed, easy-to-follow teaching style
• Instruction designed specifically for homeschool students
The course includes approximately 7 hours of video instruction following the Jacobs Geometry textbook.
A Geometry Course Designed for Homeschool Families
Teaching high school math can feel intimidating for many parents.
This course is designed to make geometry manageable, structured, and successful for both students and parents.
You don’t have to figure everything out on your own.
You’ll receive:
• A detailed (weekly and daily) syllabus showing exactly which lessons and problems to complete
• Chapter tests, midterm, and final exams
• Detailed answer keys and solutions
• A grading guide that makes evaluating tests simple
• Email homework support from AskDrCallahan when questions arise
Everything is organized so your student can stay on track throughout the school year.
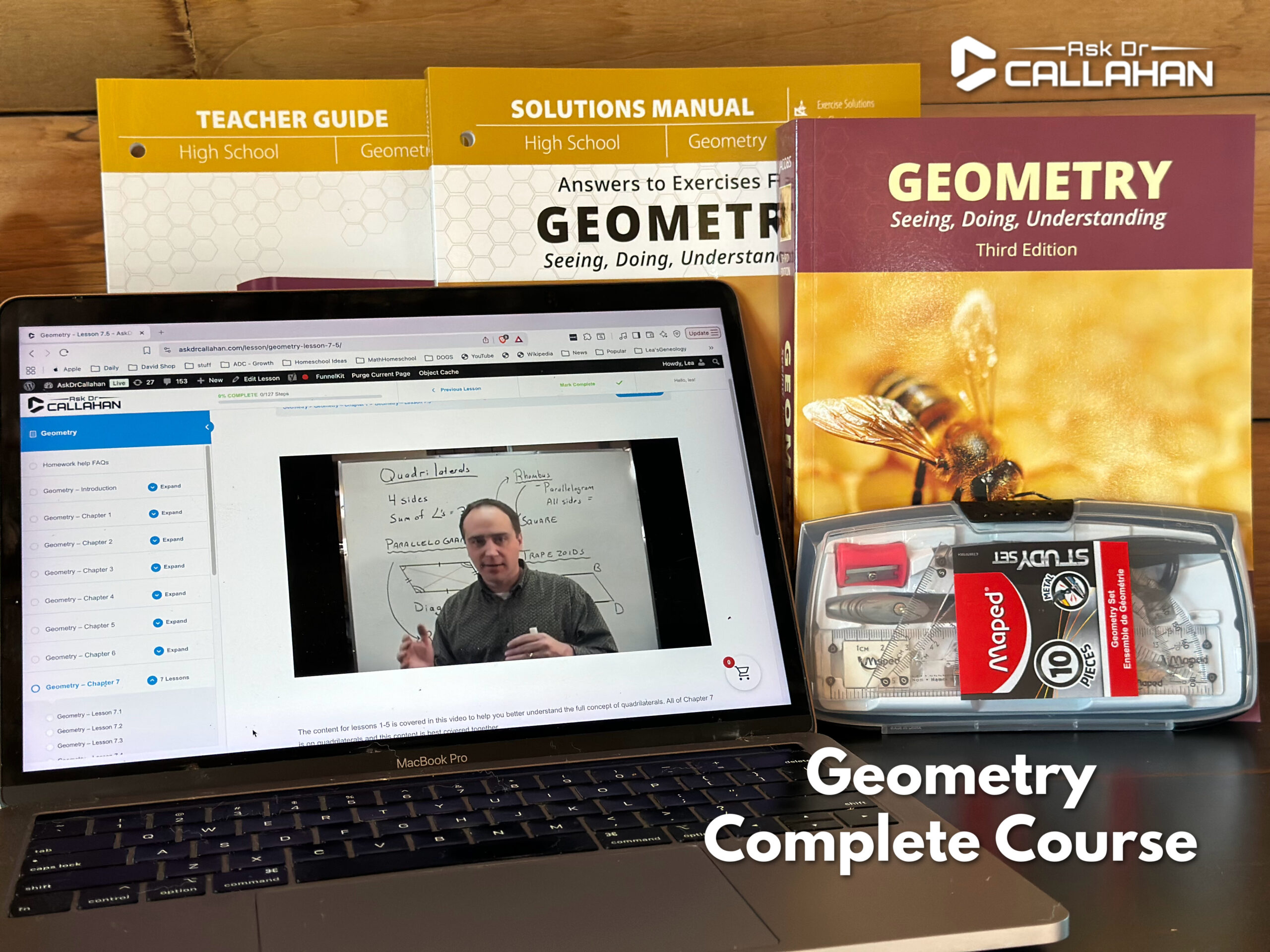
Everything Included in the Geometry Complete Course
Your package includes everything needed to complete a full high school geometry course.
✔Jacobs Geometry Textbook
Harold Jacobs’ Geometry: Seeing, Doing, Understanding is widely respected for its clear explanations and engaging approach that helps students truly understand geometry.
✔Jacobs Teacher’s Guide
Includes tests, answer keys, and a daily schedule to help organize the course.
✔Jacobs Solutions Manual
Provides detailed solutions showing how to work through the problems step-by-step.
✔AskDrCallahan Online Video Instruction
Approximately 7 hours of teaching videos covering the most important concepts in the course.
✔AskDrCallahan Teacher’s Guide
Includes AskDrCallahan’s detailed syllabus, selected problem schedule, and grading guide to make the course easy for parents to manage.
✔Geometry Drawing Kit
Includes compass, protractor, ruler, and triangles used for geometric constructions.
✔Homework Help
Email us for help with all your homework questions.
Prepare Your Student for Higher Math
Jacobs’ Geometry has helped thousands of students develop the reasoning skills needed for advanced math and science.
By focusing on understanding, logic, and real applications, this course prepares students for:
• Algebra II
• Trigonometry
• Physics and other sciences
• ACT and SAT math sections
• College-level math
Students don’t just complete geometry — they build the mathematical thinking skills needed for the future.
Common Questions
Sample Videos from the Course
Additional information
| Weight | 9 lbs |
|---|---|
| Dimensions | 12 × 10 × 8 in |